AI Snake Game
Table of Contents
- Introduction and Scope
- My Motivation
- Goals
- Technical Components
- Environment Setup
- Configuration File Management
- Running the Snake Game
- Running the AI Snake Game
- Understanding the Reward System
- AI Snake Game Keyboard Shortcuts
- Codebase Architecture
- Introducing the Concept of Level 2
- Introducing the Level 2 Neural Network Architecture
- Introducing the Dynamic Neural Network Architecture
- Command Line Options
- Specifying Numbers of Nodes and Layers
- Adding Layers On The Fly
- Adding Dropout Layers
- Matplotlib Game Score Plot
- Using Batch Scripts to Fine Tune Hyperparameters
- Highscore Files
- Limitations and Lessons Learned
- Links
- Credits and Acknowledgements
Introduction and Scope
This project is based on the classic Snake Game where the player uses the arrow keys to control a snake.

As the snake moves, the goal of the game is to maneuver the snake so that it eats the food. Every time the snake eats a block of food it grows one segment. The game ends when the snake hits the edge of the screen or the food. The score corresponds to the number of food chunks the snake has eaten.
The AI Snake Game has an AI controlling the snake. At the beginning of the game the AI is pretty terrible, but after about twenty-five games it has a length of eight and after a couple hundred or more games it can achieve scores of forty or more!
My Motivation
It is clear to me that the next new thing is Artificial Intelligence. It’s amazing how quickly it is pervading society! AI assistants, AI generated content writing, images and film. Self driving cars, movie recomendations and market analysis.
As a techie I wanted to learn how to create an AI and this project is my first foray into that arena. I did this project as an educational exercise to teach myself some of the technology that is under the hood.
Goals
I’m always trying to improve my coding skills. I know that parts of the code are pretty messy and could use a serious cleanup and re-write, but my goals do not include writing perfect code.
- Learn more Python
- Learn about PyTorch and ML
- Learn more about GitHub pages
- See how different neural network shapes affect the AI agent’s learning process
- See how different hyper-parameters affect the AI agent’s learning process
- See how adding layers on-the-fly affects the performance of the AI
- See how adding dropout layers affected the performance of the AI
- See how activating dropout layers on the fly affected the performance of the AI
- Try to get an amazing highscore :)
Technical Components
This project is written in Python. It uses the following components:
- Python - The Python programming language
- Git - Distributed version control system, not used in the game, but used to get the game
- PyGame - Python library for creating graphical games and user interfaces
- PyTorch - Backend library for AI development
- Matplotlib - Visualization library
- IPython - Used to connect PyGame and Matplotlib
Configuration File Management
IMPORTANT NOTE: If you decide to download, run and tinker with this project I want to share a hard-learned lesson: Neural networks are EXTREMELY sensitive to hyperparameters and the neural network architecture. For this reason it’s critical that you manage the INI file with extreme care. A small change in configuration can make your AI go from a super star to a dismal failure. Do not modify the AISnakeGame.ini file, make a copy and then use the --ini_file switch to point the AISim.py front-end at your custom configuration.
Environment Setup
I strongly recommend setting up a virtual environment to run and modify the AI Snake Game. You will need Python installed in order to do this. By using a virtual environment you won’t be altering the overall state of your Python installation. This will avoid screwing up programs and components on your system that use Python.
While you can easily run this on Windows, the instructions I have provided are for Linux as that is my preferred operating system. If you are running on Windows, you might want to follow the links in technical components section of this page and use information from those sites on setting up your environment. In particular, the Pyorch component.
The command below creates a virtual environment called ai_dev in your current working directory.
python3 -m venv ai_dev
Next, you’ll need to copy the code from this GitHub repository to your computer:
git clone https://github.com/nadimghaznavi/ai.git
This will download my ai git repository onto your system in a directory called ai.
You will need to install the Python libraries that the code uses. Again, you’ll want to do so in your virtual development environment. The first step is to activate the environment:
. ai_dev/bin/activate
Your prompt will change, indicating that you’re now in the virtual environment:
nadim@mypc:~$ . ai_dev/bin/activate
(ai_dev) nadim@mypc:~$
Once you have activated the virtual environment you will need to install some Python libraries. You can use pip to do so.
(ai_dev) nadim@mypc:~$ pip install matplotlib
(ai_dev) nadim@mypc:~$ pip install torch --index-url https://download.pytorch.org/whl/cpu
(ai_dev) nadim@mypc:~$ pip install pygame
(ai_dev) nadim@mypc:~$ pip install IPython
(ai_dev) nadim@mypc:~$ pip install scipy
Running the Snake Game
To run the original snake game, first activate your virtual environment, then launch the game:
nadim@mypc:~$ . ai_dev/bin/activate
(ai_dev) nadim@mypc:~$ cd ai/snake
(ai_dev) nadim@mypc:~/ai/snake$ python SnakeGame.py
Then use the arrow keys to control the snake and go for the food. Have fun!!!!
Running the AI Snake Game
To watch the AI play and learn the snake game just activate your virtual environment, navigate to the snake directory and launch the AISim.py front end:
nadim@mypc:~$ . ai_dev/bin/activate
(ai_dev) nadim@mypc:~$ cd ai/snake
(ai_dev) nadim@mypc:~/ai/snake$ python AISim.py
AI Snake Game Keyboard Shortcuts
I’ve coded in some additional keyboard shortcuts into the AI Snake game:
| Key | Description |
|---|---|
| m | Print the neural network to console |
| a | Speed the game up |
| z | Slow the game down |
| h | Stop displaying the game, while letting it continue to run |
| i | Resume displaying the game |
| m | Print the runtime neural network |
| p | Pause the game |
| spacebar | Resume the game |
| q | Quit the game |
Understanding the Reward System
There are three rewards in the AI Snake Game:
| Reward Value | Reward Description |
|---|---|
| -10 | Game over |
| +10 | Snake got a piece of food |
At the end of each move, the AI Snake Game simulation calls the AI Agent’s train_short_memory() function. The only thing this function does is call the QTrainer’s train_step() function, where the weights and bias’ are rebalanced.
Codebase Architecture
The AISim.py is the main front end to the AI Snake Game. It’s the code that you need to execute in order to run a simulation.
I have implemented a neural network architecture with three blocks; B1, B2, B3. By using the --b1_nodes, --b1_layers, --b2_nodes and so on, you can configure the number of nodes and layers in each block when you start the simulation. i
After a lot of re-design and re-factoring of the code, I have settled on the following architecture for the AI Agent:
- The initial neural network architecture is selected from the INI file settings or from the
--b1_nodes,--b1_layers,--b2_nodes… etc. I refer to this as the L10 neural network or just L10. - The L10 level also includes a ReplayMemory, Trainer and Epsilon Greedy instances.
- This L10 component handles Snake Game scores up to 10. When the AI achieves a score between 11 and 20 a new component, L20 is created with it’s own ReplayMemory, Trainer and Epsilon Greedy instances. The neural network architecture is the same as the L10 component with respect to node numbers, layers, dropout layers etc.
- When the AI achieves a score of 20 a L30 component is created… and so on, indefinitely.
- When a new L component is created, the weights and biases from the lower layer are copied in so it has the experience and the training from the lower neural network. After that, it operates independently.
- I disable the Epsilon Greedy instance by default and use my own NuAlgo instead
- Like the Epsilon Greedy object, the NuAlgo object inserts random moves into the game as part of the AI’s exploration/exploitation training process. But unlike the Epsilon Greedy, the NuAlgo is dynamic: It injects random moves based on the AI’s (poor) performance.
Codebase Components
Here’s a breakdown of the files and directories and what they are.
AIAgent.py
This file houses the AI Agent or the AI player.
AiSim.py
This is the front end to the AI Snake game. It’s the file you need to run to launch the AI Snake Game.
AISnakeGameConfig.py
This file handles reading the AI Snake Game configuration settings from the AISnakeGame.ini file.
AISnakeGame.ini
This file controls a lot of the settings for the AI simulation.
AISnakeGame.py
This a modified version of the SnakeGame.py. It’s been changed so that the AIAgent acts as the player instead of a human being.
arial.ttf
The actual snake game and AI snake game uses this file to render the scores, moves and times shown at the top of the game screen.
batch_scripts
This directory has a couple of batch scripts I wrote to run the AI Snake Game in batch mode while changing one or more parameters. You can use this to run a bunch of simulations overnight and then look at the highscore files to see how different settings affect the performance of the AI.
I included these as examples. I encourage you to author your own and experiement!
EpsilonAlgo.py
The epsilon algorithm is a standard algorithm used to inject a decreasing amount of randomness into the initial stages of the game. It implements the exploration part of exploration/exploitation in machine learning.
LinearQNet.py
The LinearQNet class houses the PyTorch neural network model. that the AI Snake Game uses. I have extended this class pretty significantly. For example, I’ve added functions to add in new layers on-the-fly with differing numbers of nodes and load and save functions to take snapshots of the running simulations.
next_ai_version.txt
This file holds a number that the code uses for the version of the simulation. It is incremented every time you run the AISim.py front end.
NuAlgo.py
This is a class I wrote to try and optimize the learning behaviour of the AI Agent. By tweaking this code and the settings in the AISnakeGame.ini I have managed to train the AI to reach a high score of 80!!
However, tuning the code and NuAlgo settings is very, very domain specific, so I have dropped this module and am no longer using the code.
QTrainer.py
This is part of the reinforcement learning that is used in this code to train the AI. It houses the optimizer that tweaks the neural network settings as the game runs.
README.md
A standard GitHub README file. It points at this page.
reference_sims
A few simulation files I saved, because they performed well. You can copy them into the sim_data directory and load them with the -v switch to run them.
ReplayMemory
This class implements a replay memory function, essentially a Python deque to store a fixed number of states which are used for training.
sim_data
This directory is automatically created when you run the AISim.py script. Here are three example files that were created during a simulation run:
- 409_sim_checkpoint.ptc - A Simulation checkpoint file
- 409_sim_desc.txt - A file that contains some of the simulation settings
- 409_sim_highscore.csv - A CSV file with highscores from the simulation run
SnakeGameElement.py
This contains some helper classes used by the AISnakeGame.
SnakeGamePlots.py
This has the plot() function that launches the matplotlib pop-up window that graphs out the game scores in realtime as you run the simulation.
SnakeGame.py
The original Snake Game that you can play.
Introducing the Concept of Level 2
I implemented this concept and then took it back out and replaced it with the more dynamic one-neural-network-for-every-10-points as described in the codebase architecture section of this document. I included this section to show the evolution of the code architecture.
The Snake Game becomes significantly more challenging when the Snake’s length is more than twice the width of the board. At that point the strategy needed to continue to improve the scores doesn’t just rely on finding the food, it also includes the challenge of moving in a manner such that collisions with the Snake itself are avoided.
I defined level 1 as scores up to this point. E.g. Given a board size of 40x40, with a snake segment and a food segment occupying one square, the level one score would be 40. Scores above 40 are considered level 2.
A very basic and simple neural network architecture consisting of one layer with 100 nodes is easily able to achieve level 1 scores. Reaching level 2 e.g. consistent scores in the 50 to 60 range on a 20x20 board is much, much harder.
Introducing the Level 2 Neural Network Architecture
In my quest to improve the AI Agent’s ability to play the Snake Game, I have implemented what I called a Level 2 neural network. This is basically a second, independent neural network that is only fed data when the game score in the level two range ie. scores from 41 on.
This approach was somewhat successful, but achieving scores above 50 proved difficult and finding the magic hyperparameters for the NuAlgo and Epsilon required a ton of simulation runs. In the end I abandoned this approach.
Command Line Options
I’ve implemented quite a few options to the AISim.py front end:
usage: AISim.py [-h] [-b1n B1_NODES] [-b1l B1_LAYERS] [-b2n B2_NODES] [-b2l B2_LAYERS] [-b3n B3_NODES]
[-b3l B3_LAYERS] [-c CUSTOM_DATA_DIR] [-d DISCOUNT] [-ds DROPOUT_STATIC] [-e EPSILON]
[-he HEADLESS] [-i INI_FILE] [-l LEARNING_RATE] [-mg MAX_GAMES] [-ms MAX_SCORE]
[-nbg NU_BAD_GAMES] [-nps NU_PRINT_STATS] [-nus NU_SCORE] [-nuv NU_VALUE] [-r RANDOM_SEED]
[-re RESTORE] [-s SPEED]
Running the AISim.py frontend with the -h switch provides a more detailed description of these options. IMPORTANT NOTE: I am still tinkering with this project, so like they say at Microsoft, the implementation is the specification…
Specifying Numbers of Nodes and Layers
I have implemented switches to select the number of layers and the number of nodes in each layer when starting the simulation. I’ve coded in three blocks where the number of nodes in each block can be different. The code takes care of making sure the layer shapes line up so that the resulting neural network is valid. These options are controllec by the following switches:
- Block 1 configuration:
--b1_nodesand--b2_layers - Block 2 configuration:
--b2_nodesand--b2_layers - Block 3 configuration:
--b3_nodesand--b3_layers
These features allow easy experimentation with different neural network architectures.
Adding Layers On The Fly
I was curious about the effect of adding layers on the fly. You may want to experiment with this option using the --b1_score, --b2_score and --b3_score which are features that drop in a B1, B2 or B3 layer when the AI reaches a particular score. What I learned was that adding layers on-the-fly disrupts the performance of the AI (no big surprise). When adding a B1 layer i.e. one that matches the shape of the existing B1 layer is much less disruptive: The AI recovers relatively quickly and carries on. Adding a new B2 layer i.e. when you didn’t have any B2 layers and the shape is different than the B1 layer is extremely disruptive to the perfomance of the neural network.
These features weren’t helpful in achieving higher scores, so I removed the functionality.
Adding Dropout Layers
I have implemented a --dropout-static switch that instructs the AISim.py to create PyTorch nn.Dropout layers with a P Value that is passed in with an argument to the --dropout-static switch. The code takes care of inserting these dropout layers are in between the hidden B1, B2 and B3 hidden layers.
I implemented this feature to see if adding additional noise to the simulation would stop the AI from getting stuck in sub-optimal game strategy. It’s stuck now: When the snake reaches a length that is more than twice the width of the board (I’m using a 20x20 board), then there is an added challenge. With my current setup, the AI can achieve scores of up to around 50, but not really any higher. At that point in the game, the AI has settled into a strategy of moving the snake around the edge of the screen and then cutting through the middle to get the food. It continues to the other edge and then circles again. While this strategy is good for scores up to 40, it fails to reach scores in the 60s because it ends up hitting itself.
I currently have a batch script that is running simulations with varying learning rates to see if tweaking that value will help it get past this challenge.
Using Batch Scripts to Fine Tune Hyperparameters
Fine tuning the hyperparameters and neural network architecture are key elements in finding successful neural network configurations. Scripting these explorations is a systematic and efficient way to execute this process. Here is an example of batch script I am using that does 10 simulation runs that vary the learning rate of the configuration from 0.0005 to 0.0015:
#!/bin/bash
#
CONFIG=configs/B1_100_nodes-B2_200_nodes-B3_400_nodes-dropout_0.2.ini
MAX_GAMES=800
# Learnign rate, testing from 0.0005 to 0.0015 and skipping 0.001,
# because I already have that simulation result.
COUNT=5
while [ $COUNT != 10 ]; do
LR=0.000${COUNT}
python AISim.py \
-i $CONFIG \
--max_games $MAX_GAMES \
-l $LR
COUNT=$((COUNT+1))
done
COUNT=1
while [ $COUNT != 6 ]; do
LR=0.001${COUNT}
python AISim.py \
-i $CONFIG \
--max_games $MAX_GAMES \
-l $LR
COUNT=$((COUNT+1))
done
Highscore Files
The simulation runs produce a CSV high scores file which allows me to easily analyse the results of the batch runs:
$ echo; for x in $(ls *high*); do echo $x; cat $x; echo; done
800_sim_highscore.csv
Game Number,High Score
0,0
9,1
120,2
265,5
801_sim_highscore.csv
Game Number,High Score
0,0
15,1
171,2
247,3
268,4
292,5
802_sim_highscore.csv
Game Number,High Score
0,0
11,1
90,2
.
.
.
Matplotlib Game Score Plot
The AISim.py front end launches a matplatlib window that graphs out game score and average game score as the simulation runs.
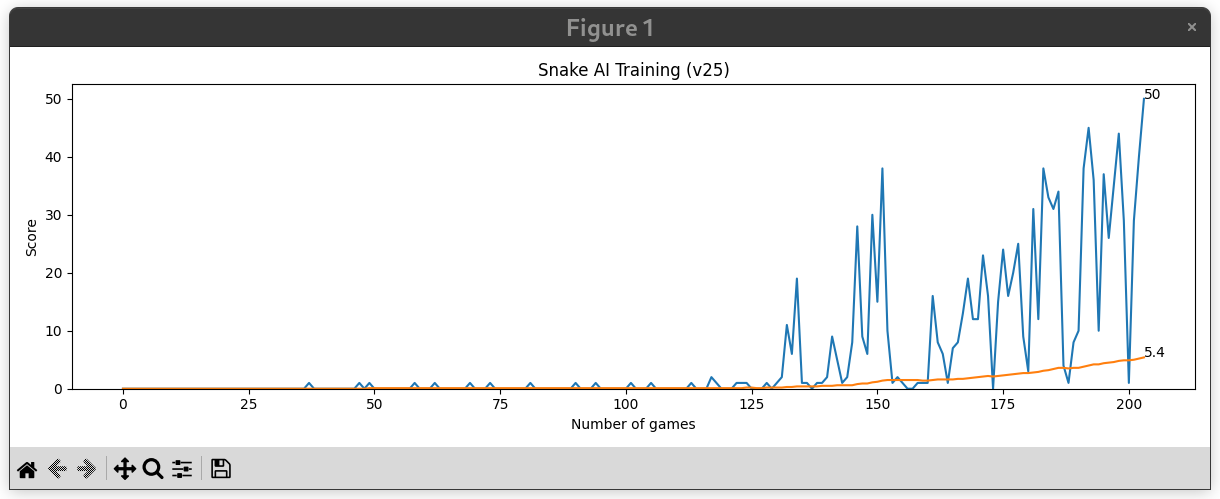
Limitations and Lessons Learned
So what are the limits that this implementations is hitting? Well, the AI reaches what I call level 1 where the length of the snake is over twice the width or height of the board. This is due to the strategy that the AI develops:
The strategy that the AI develops is to circle around the endge of the board. Once it is lined up with the food it moves through the center, eats the food and continues until it reaches the other side of the board. Then it circles again. This algorithm fails when the snake gets too long and it hits itself.
I found a paper, Playing Atari with Deep Reinforcement Learning which seems to identify and address this problem. Here’s the first paragraph from the introduction:
“Learning to control agents directly from high-dimensional sensory inputs like vision and speech is one of the long-standing challenges of reinforcement learning (RL). Most successful RL applications that operate on these domains have relied on hand-crafted features combined with linear value functions or policy representations. Clearly, the performance of such systems heavily relies on the quality of the feature representation.”
This describes the situation exactly. Here is what they developed:
“We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards.”
I was quite surprised to discover that the AI Agent learns quickly and effectively with a very small and simple neural network. When I started I was using 512, 1024 and 2048 for the number of nodes and I was using multiple layers. What I found was that a single layer with only 80 nodes outperformed the simulations with large numbers of nodes and layers. It’s truly impressive how effective even simple neural networks are at solving problems.
Food for thought!!! :)
Links
Credits and Acknowledgements
This code is based on a YouTube tutorial Python + PyTorch + Pygame Reinforcement Learning – Train an AI to Play Snake by Patrick Loeber. You can access his original code here on GitHub.
Thank you Patrick!!! You are amazing!!!! :)